
FBK and the Centre for Intelligent Sensing of Queen Mary University London have activated a joint project on advanced solutions for audio-visual processing. In particular, the project focuses on the use of heterogeneous egocentric devices in challenging and unconstrained environments. Two PhD grants are jointly funded by FBK and QMUL.
Some scientific achievement produced by this collaboration are listed below.
Multi-modal model Adaptation for Target ID on Egocentric Data
Recently, the number of devices equipped with both audio and video sensors (wearable cameras, smart-phones) has been growing continuously. This suggests investigating effective solutions for joint audio-video processing, which overcome limitations of single-modal systems and to open new application context.
State of the art methods typically focus on early feature stacking or late combination of scores of mono-modal systems. These approaches do not really exploit the potential of the multi-modal information. For instance, early fusion cannot deal with intermittent features and late fusion just skips the unreliable modality. Moreover, none of these methods employ multi-modality to reduce model mismatch or to allow training on very small datasets. Conversely, a joint processing of the audio and video information, fully aware of their complementarity, can help circumventing critical issues of single modalities. The idea is to move beyond traditional combination methods by introducing a cross-modal aware processing where elaboration and modelling of a modality depend on the other sensor.
Target (person) identification is one of the most common tasks in audio-video processing, which can greatly benefit from an effective integration of the acoustic and visual streams.
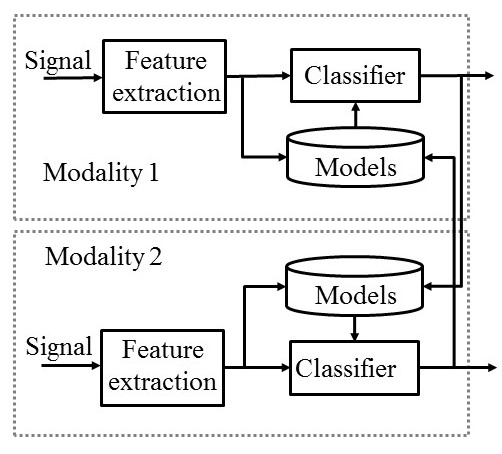
In [1] and [2] we developed a multi-modal unsupervised continuous adaptation of each single-modal model using the information from the other modality: as soon as a new observation is available, the related models (audio and/or video) are updated to mitigate possible mismatches and to improve weak models.
In particular, we focused on egocentric data acquired by wearable devices, which are particularly interesting. They pose a series of severe challenges (rapidly varying environmental conditions, limited training material, highly intermittent features, very short interactions), which stress the potential of the complementarity of audio-visual data
More details about the data and the processing chain are available here.
A brief presentation the proposed method with some intermediate results is available in these Slides.
[1]A. Brutti, A. Cavallaro, “On-line cross-modal adaptation for audio-visual person identification with wearable cameras”, IEEE Transactions on Human-Machine Systems, to appear, 2016
[2]A. Brutti, A. Cavallaro, “Unsupervised cross-modal deep-model adaptation for audio-visual re-identification with wearable cameras”, ICCV Workshop CVAVM, 2017
Audio-Visual 3D Tracking
Compact multi-sensor platforms are portable and thus desirable for robotics and personal-assistance tasks. However, compared to physically distributed sensors, the size of these platforms makes person tracking more difficult. To address this challenge, we proposed Audio Visual 3D Tracker (AV3T) [1] to track multi-speaker 3D, using the complementarity of audio and video signals captured from a small-size co-located sensing platform consisting of an RGB camera mounted on top of a circular microphone array.
Key Points
- Face detector driven system
- Selective visual likelihoods between discriminative (face detection) and generative (color spatio-gram) models
- Video-constrained audio processing to limit uncertainty in depth estimation
- Effective cross-modal combination in a PF framework
The proposed method was tested on the CAV3D DATASET.
More details and video demos are available here
[1] X. Qian, A. Brutti, O. Lanz, M. Omologo and A. Cavallaro, “Multi-speaker tracking from an audio-visual sensing device,”in IEEE Transactions on Multimedia. doi: 10.1109/TMM.2019.2902489
CROSS-MODAL KNOWLEDGE TRANSFER
Multi-modal learning relates information across observation modalities of the same physical phenomenon to leverage complementary information. One way to exploit this complementarity is to transfer knowledge from the best performing modality (for a given task) to the other modality.
SEW (Stronger Enhancing Weaker) [1] is a framework that uses:
- cross-modal translation and
- correlation-based latent space alignment
in combination with a compound loss, to improve the representations of a worse performing (or weaker) modality.
[1]V. Rajan, A. Brutti, A. Cavallaro, “ROBUST LATENT REPRESENTATIONS VIA CROSS-MODAL TRANSLATION AND ALIGNMENT”, ICASSP 2021 https://arxiv.org/abs/2011.01631
