
Cutting-edge AI Applied to Speech
Currently, my main research direction involves the development and application of cutting-edge AI paradigms to speech domains, in particular ASR and SLU.
- Architectular approaches: dynamic and efficient neural architectures
- ML methods applied to speech
ML methods applied ot speech
Below a couple of examples.
Continual Learning for SLU
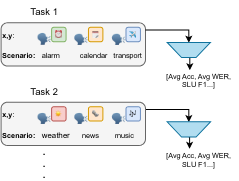
The capabilities of continually learning new tasks is a crucial feature for applications based on spoken language understanding.
We are investigating solutions based on knowledge distillation and contrastive learning in multimodal domains (speech+text) to reduce the impact of catastrophic forgetting
Federated Learning
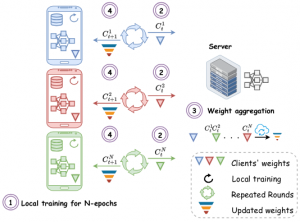
Federated Learning has been widely used as an effective decentralized technique that collaboratively learns a shared prediction model while keeping the data local on different clients. Unfortunately, fine-tuining large foundation models for ASR purposes is often not viable for several reasons.
We are investigating methods tailored to ASR and speech processing which allow:
- efficient client-server communication via PEFT
- use of etherogeneous architectures for different edge devices via early exiting
Dynamic models for speech processing
The ability to dynamically adjust the computational load of neural models during inference is crucial for on-device processing scenarios characterised by limited and time-varying computational resources. Dynamic architectures enable resource-aware processing, where a single model can be used on heterogeneous devices, as well as result-aware processing, where the model selects the earliest exit that achieves the same performance as the entire network.
Early Exits
A solution is represented by “early-exit” architectures that introduce intermediate exit branches. The input is not processed by all layers of the neural network but only a subset of them, returning the result at an intermediate layer and bypassing operations in the layers not traversed.
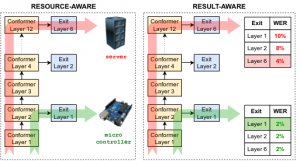
We used EE in ASR applications (using pre-trained models as well as models trained from scratch), also in Federeating Learnign settings.
Layer Dropping
An alternative solutioin is layer-dropping that skips some of the transfomer layers during inference to reduce the computational costs. We have solutions based on random dropping or input-dependent dropping via a specific router. This solution is applied to a variety of speech and audio processing tasks

Spoken Language technologie
Besides working on cutting-edge AI applied to speech, I am working on core speech technologies, in particular for ASR, investigatin mainly 2 directions:
- Speech LLM architectures, leveraging SLAM-ASR paradigm
- Low-resourced langauge technologies
Sound Event Detection for IoT embedded platforms
In collaboration with my colleagues of the E3DA research team, I am working towards porting SED state-of-the-art solutions on IoT low-power platforms. This activity is part of the City Sensing project of the Digital Society line, which aims at developing technologies for smart cities and communities.
The first achievement was the implementation on an embedded device of a real time demonstrator capable of achieving state-of-the-art performance on UrbanSound8k.

Speaker diarization and verification
I address the speaker recognition problem in presence of reverberant distant speech. In particular, model adaptation and effective combinations of multiple distributed microphones mitigate the effects of reverberation. [IS13, IS15, odissey16]
Currently, I am focusing on speaker diarization, also on telephone speech, implementing the most advanced state-of-the-art approaches based on deep learning (i.e. speaker embeddings).
In particular, on-line supervised clustering is emerging as an interesting direction to directly optimize the clustering stage on the data.

Check out our github repo

Audio-Visual processing
Recently, in collaboration with the Center for Intelligent Sensing at Queen Mary University London, I have been working on multimodal processing, focusing in particular on person recognition with sensors for person-centered scenarios (i.e. using wearable devices). Specifically, the main focus was on unsupervised on-line adaptation of the target models.
We have also investigated audio-visual person tracking for co-located sensing platforms and we are recently addressing multimodal emotion recognition.
Visit the page of the audio-visual processing joint project with QMUL for more details.
Audio-Video people tracking
Initially, this activity was conducted in cooperation with Oswald Lanz of the TEV research unit. The goal was to track the positions and head poses of multiple subjects in an environment equipped with multiple distributed microphones and cameras.
We implemented a generative Bayesian framework which combines audio and video information at likelihood level, substantially improving the robustness of single modalities.
 |
 |
In collaboration with Queen Mary University London, we have investigated similar paradigms to achieve 3D localization of multiple targets using 1 single camera co-located with a compact microphone array. Some more details are available here: audio-visual processing.
—> CAV3D DATASET is now available for download. <—
Localization of acoustic sources in multi-microphone environments:
My first research domain, addressed during my PhD, was localization of acoustic sources using both compact microphone arrays and distributed microphone networks.
Main achievements were related to:
- acoustic maps as the Global Coherence Field (GCF),
- localization and tracking of multiple source (paper), using generative bayesian approaches (paper)
- Estimation of source orientation based on Oriented Global Coherence Field (OGCF) (paper)
I have also applied BSS based processing for tracking of multiple sources (paper)
Check out some demos from our youtube channel:


Past projects
- DIRHA: development of the multi-room, multi-microphone front-end. Demonstrator
- SCENIC: environment aware localization of multiple sources and estimation of the source emission pattern
- DICIT: source localization
Other activities
- JSALT senior or part-time member: 2019, 2023
- Visiting researcher at Queen Mary University London during summer 2015
- PhD committee at Vrije Universiteit Brussel
- PhD committee at Tampere University of Technology
- PhD committee at University of Alcala’
- PhD reviewer at University of Modena and Reggio Emilia
- Since 2020: teaching Speech Technology Lab at the Faculty of Education of the University of Bolzano